Theory to Impact
Today's algorithms learn what you want while shaping what you want. The result is sycophancy, echo chambers, epistemic harm, polarization, mental health crisis — preferences frozen at their least-examined. We build principled alignment alternatives: aligned not with the small, dopamine self, but with the big, reflective self.
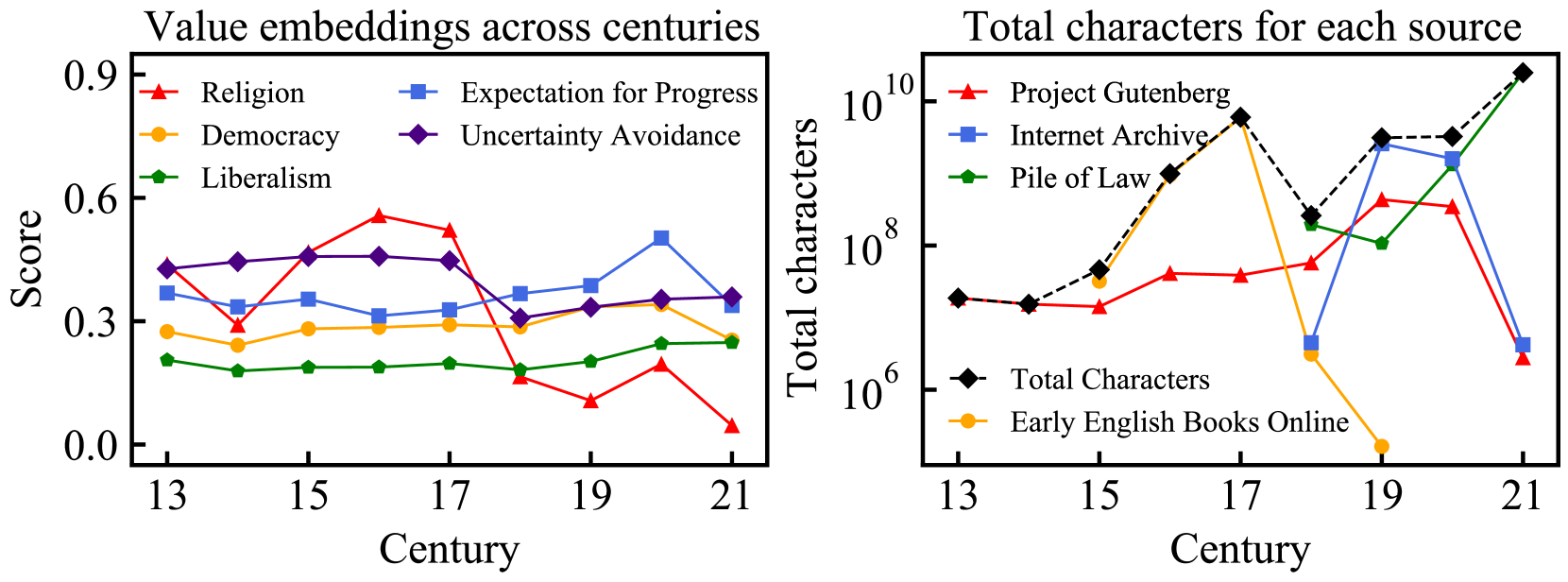
A temporal alignment framework that adds a historical dimension to RL-based alignment, using nine centuries of text and 18 historical language models. Enables AI to track and align with moral progress across time rather than freezing a snapshot of current values.
LLMs acting as epistemic technologies systematically amplify biases and errors in ways that drive knowledge collapse and value lock-in across populations. A position paper building the theoretical and empirical foundation for our research agenda.
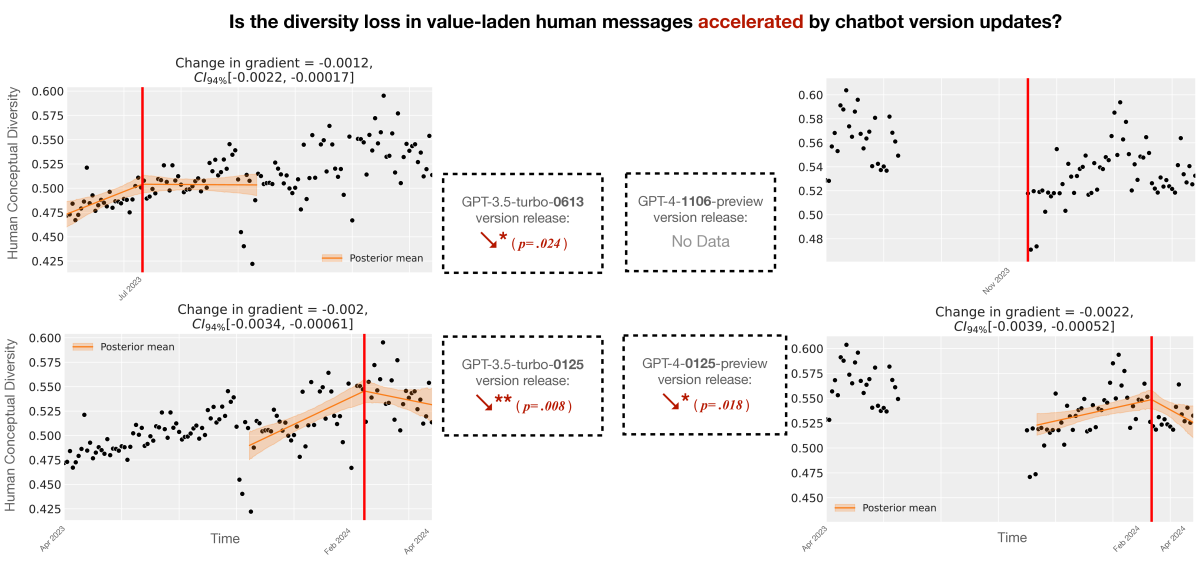
Human-AI feedback loops can freeze collective values in place — producing stagnation by algorithm. Demonstrated through simulation of human-AI interaction dynamics and causal inference on real-world ChatGPT usage data, showing how repeated exposure to AI outputs entrains beliefs at scale.
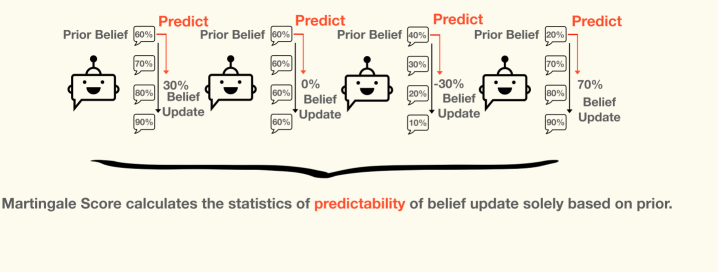
An unsupervised, regression-based metric that detects when LLMs deviate from rational Bayesian belief updating. Iterative reasoning often deepens confirmation bias rather than advancing truth-seeking. The Martingale Score correlates with ground-truth accuracy where labels are available, without requiring them.
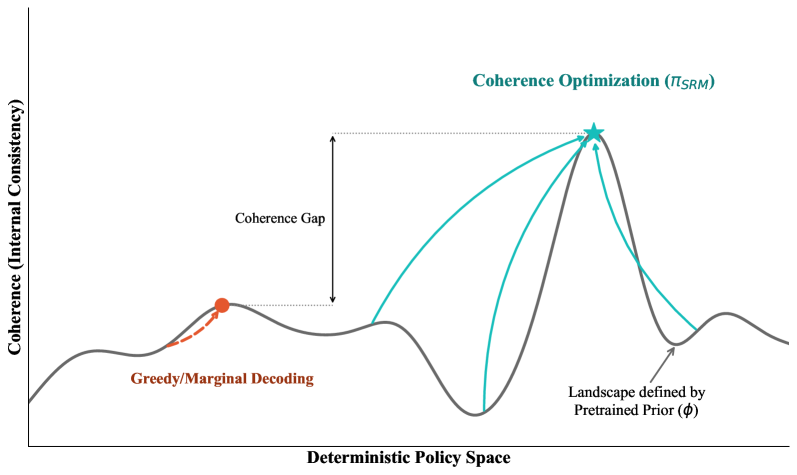
Debate, bootstrapping, and self-play are unified as special cases of coherence optimization — finding the most compressible, jointly predictable context-to-behavior mapping. Proves equivalence to description-length regularization and establishes optimality for semi-supervised elicitation from pretrained models.
A comprehensive survey and synthesis of how AI systems shape human beliefs, amplify biases, and drive epistemic harm — from sycophancy and echo chambers to societal-scale polarization — with a framework for understanding and intervening on AI influence.
-
ACL 2025 · Best Paper
-
ACL 2025
-
ACL 2025 Findings
-
JAIR · NeurIPS 2024 Workshop · Best Paper
-
NeurIPS 2024 · Oral
-
ACM Computing Surveys 2025
-
CogInterp @ NeurIPS 2025
-
Preprint 2025
-
ICLR 2026
-
ICLR 2026
-
Preprint 2026
-
ACM FAccT 2023