Abstract
Human values are not fixed: they evolve as people encounter new experiences, arguments, and evidence. Yet AI systems trained on human feedback learn a static snapshot of preferences — and then shape the very interactions that could have updated them. We call this dynamic the Lock-in Hypothesis: human-AI feedback loops systematically suppress the exploration and revision that moral progress requires, freezing collective values in place and producing stagnation by algorithm.
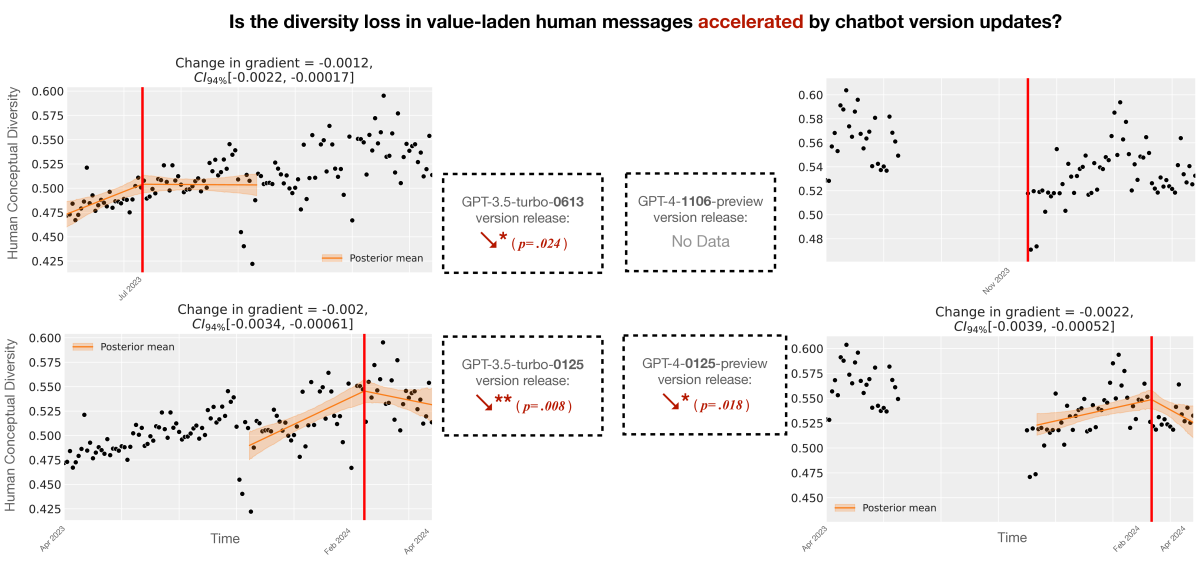
We provide two forms of evidence. First, we simulate human-AI interaction dynamics using a computational model of belief updating, showing that RLHF-style feedback loops create attractor states around whatever preferences were prevalent at training time. Second, we conduct causal inference on real-world ChatGPT usage data, finding that repeated AI exposure entrains user beliefs toward AI outputs across ideologically diverse populations. Together, these results suggest that widely deployed AI systems may already be constraining the diversity of human values in ways that compound over time — not through any single dramatic intervention, but through the accumulated weight of everyday interactions.
Cite
@inproceedings{qiu2025lockin,
title = {The Lock-in Hypothesis: Stagnation by Algorithm},
author = {Qiu, Tianyi and He, Zhonghao and Chugh, Tushar
and Kleiman-Weiner, Max},
booktitle = {Proceedings of the 42nd International Conference on
Machine Learning},
year = {2025},
url = {https://thelockinhypothesis.com}
}