Abstract
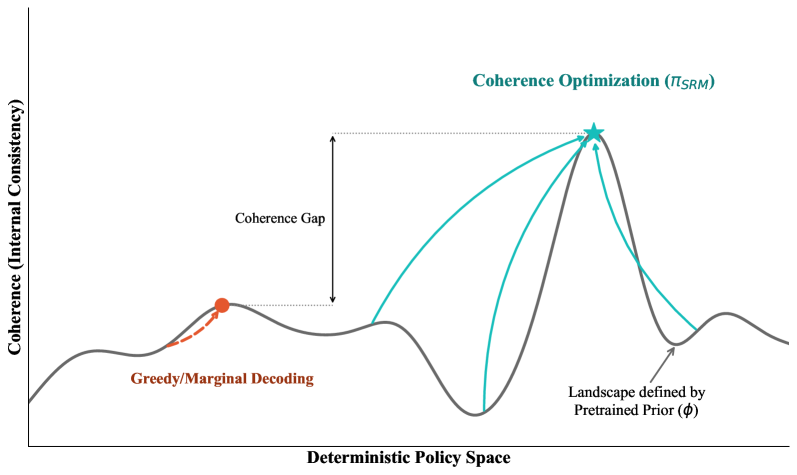
Self-improvement methods for language models — including debate, bootstrapping, self-play, and consistency-based training — appear mechanistically distinct but share a common objective: increasing the internal coherence of the model's context-to-behavior mapping. We formalize this intuition by defining coherence optimization as the problem of finding the most compressible, jointly predictable mapping across context-response pairs, and prove that this objective is equivalent to description-length regularization over the model's effective hypothesis class.
Under this framework, we show that debate, self-play, and bootstrapping are each special cases of coherence optimization differing only in how they sample contexts and constrain the response space. We further establish optimality guarantees for semi-supervised elicitation from pretrained models: when the base model already encodes latent structure, coherence optimization recovers it with minimal labeled data. These results provide a principled theoretical lens on why self-improvement works, when it fails, and how different methods trade off sample efficiency against coverage.
Cite
@article{qiu2026coherence,
title = {Self-Improvement as Coherence Optimization: A Theoretical Account},
author = {Qiu, Tianyi and Ismail, Ahmed and He, Zhonghao and Feng, Shangding},
journal = {arXiv preprint arXiv:2601.13566},
year = {2026},
url = {https://arxiv.org/abs/2601.13566}
}